
自然言語処理の核となる考え方を理解し、
ビジネスに役立てる
スマートスピーカーの普及や音声認識の精度向上など、ディープラーニングに基づく自然言語処理(NLP)による様々なタスクでの実用レベルの達成を受けて、自然言語処理のビジネス活用の機運が高まっています。
しかし、これらの実用レベルの達成がGAFAをはじめとしたビックテックによって行われてきた一方、大量のテキスト情報を有する個社レベルにおいては、自然言語処理の技術が十分に理解・活用されているとは言えない状況です。
そこで本講座では、伝統的な手法から最先端手法(word2vec、RNN、Transfomer、BERT)までを幅広く取り上げ、それらに共通する昨今の自然言語処理の核となる考え方を解説し、様々な立場でビジネスに役立つ自然言語処理の考え方を身につけます。
理論の説明と合わせて、Python/Pytorchによる主要技術の実装を行います。さらに、ビジネスへの応用を想定した実践的な課題を通し、理論を実務へ応用できるスキルも身に付けます。
講座の特長
- 1
ハンズオンを通じて、理論から実装までのNLP実装スキルを体得
- 2
数式の丁寧な解説によって自然言語処理の各手法を徹底解剖



得られる知識・スキル
-
 様々なNLPタスクに対応可能な知識形態素解析やWord2Vecなどの汎用性の高い前処理を理論から理解し、正しく利用することができるようになります。
様々なNLPタスクに対応可能な知識形態素解析やWord2Vecなどの汎用性の高い前処理を理論から理解し、正しく利用することができるようになります。 -
 ディープラーニングを用いた最先端のNLPの手法AttentionやBERTといった最新のモデルを理解し、実務で扱う種々のタスクに活用できるようになります。
ディープラーニングを用いた最先端のNLPの手法AttentionやBERTといった最新のモデルを理解し、実務で扱う種々のタスクに活用できるようになります。 -
 PyTorchを用いたハンズオンで、実務で役立つ実装スキル利便性と広範性を両立したニューラルネットワークのライブラリであるPyTorchの利用法をハンズオンによって体得し、様々なモデルの実装ができるようになります。
PyTorchを用いたハンズオンで、実務で役立つ実装スキル利便性と広範性を両立したニューラルネットワークのライブラリであるPyTorchの利用法をハンズオンによって体得し、様々なモデルの実装ができるようになります。
こんな方におすすめ
- 現場で使える自然言語処理技術を基礎から最新手法まで一気に習得したい方
カリキュラム
DAY1DAY2DAY3DAY4
自然言語処理(NLP)とは
- NLP のタスクとビジネス活用事例
- NLP における困難と現代的手法
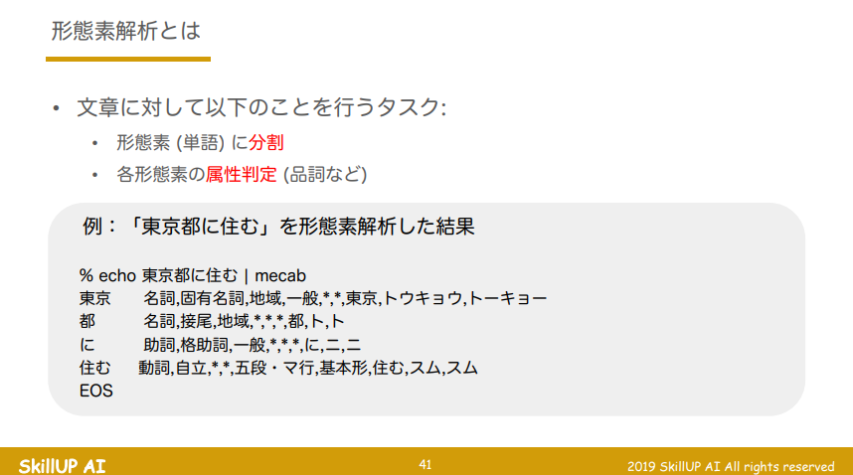
形態素解析
- 形態素解析とは
- アルゴリズム概要
など全4トピックス(ハンズオン含む)
Bag of Words(BoW)
- Bag of Words(BoW)とは?
- BoWのモチベーション
など全4トピックス(ハンズオン含む)
カリキュラムは変更となる場合がございます。
担当講師

スキルアップAI講師。横浜国立大学大学院 環境情報学府 情報メディア環境学専攻(現:情報環境専攻)修了。修士(情報学)。高専時代に画像認識に対して興味を持ったことがきっかけで、現在はDeep Learningや機械学習、進化計算などの人工知能分野におけるアルゴリズムの研究開発やコンサルティングに従事。日本ディープラーニング協会の2018年度・2019年度E資格合格者、2018年度G検定合格者。著書「徹底攻略ディープラーニングE資格エンジニア問題集」(インプレス)。2025 Microsoft Top Partner Engineer Award(Modern Work・Copilot部門)受賞。
ハンズオン:Google Cloud Platform を用いた GPU 環境の構築
PyTorch
- ハンズオン:PyTorchの基礎
- ハンズオン:torchtextの利用
など全3トピックス(ハンズオン含む)
Word2Vec
- BoW の問題点
- Word2Vec の概要
など全4トピックス(ハンズオン含む)
カリキュラムは変更となる場合がございます。
担当講師
スキルアップAI講師。横浜国立大学大学院 環境情報学府 情報メディア環境学専攻(現:情報環境専攻)修了。修士(情報学)。高専時代に画像認識に対して興味を持ったことがきっかけで、現在はDeep Learningや機械学習、進化計算などの人工知能分野におけるアルゴリズムの研究開発やコンサルティングに従事。日本ディープラーニング協会の2018年度・2019年度E資格合格者、2018年度G検定合格者。著書「徹底攻略ディープラーニングE資格エンジニア問題集」(インプレス)。2025 Microsoft Top Partner Engineer Award(Modern Work・Copilot部門)受賞。
自然言語処理におけるRecurrent Neural Network(RNN)
- モチベーション
- 再帰型ニューラルネットワークとは
など全5トピックス(ハンズオン含む)
Sequence to sequence(seq2seq)とattention
- Seq2Seq
- アテンション
など全4トピックス
言語モデル
- 言語モデルとは?
- 言語モデルの構築手法
など全4トピックス
カリキュラムは変更となる場合がございます。
担当講師
スキルアップAI講師。横浜国立大学大学院 環境情報学府 情報メディア環境学専攻(現:情報環境専攻)修了。修士(情報学)。高専時代に画像認識に対して興味を持ったことがきっかけで、現在はDeep Learningや機械学習、進化計算などの人工知能分野におけるアルゴリズムの研究開発やコンサルティングに従事。日本ディープラーニング協会の2018年度・2019年度E資格合格者、2018年度G検定合格者。著書「徹底攻略ディープラーニングE資格エンジニア問題集」(インプレス)。2025 Microsoft Top Partner Engineer Award(Modern Work・Copilot部門)受賞。
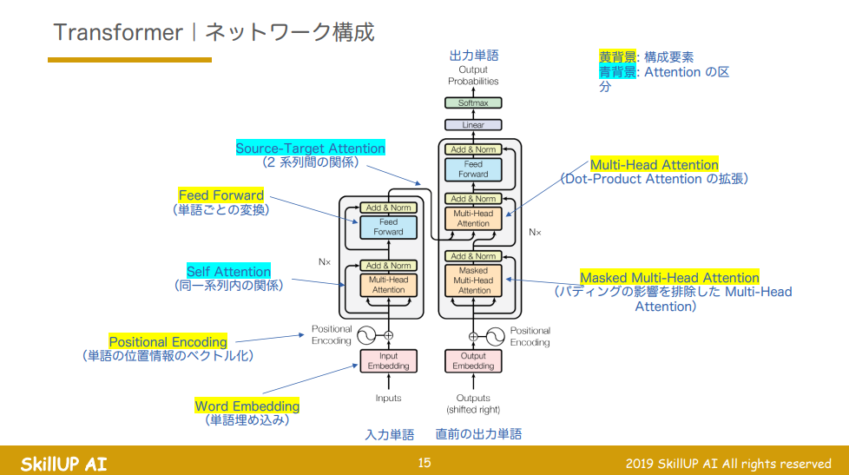
Transformer
- Embedding
- Self Attention
など全5トピックス
BERT
- Tokenizer
- ネットワーク構成
など全6トピックス(ハンズオン含む)
AutoML
- AutoMLの概要
- ハンズオン:AutoML Natural Languageを使ったテキスト分類
カリキュラムは変更となる場合がございます。
担当講師
スキルアップAI講師。横浜国立大学大学院 環境情報学府 情報メディア環境学専攻(現:情報環境専攻)修了。修士(情報学)。高専時代に画像認識に対して興味を持ったことがきっかけで、現在はDeep Learningや機械学習、進化計算などの人工知能分野におけるアルゴリズムの研究開発やコンサルティングに従事。日本ディープラーニング協会の2018年度・2019年度E資格合格者、2018年度G検定合格者。著書「徹底攻略ディープラーニングE資格エンジニア問題集」(インプレス)。2025 Microsoft Top Partner Engineer Award(Modern Work・Copilot部門)受賞。
講座概要
| 講座名 | 現場で使える自然言語処理実践講座 |
|---|---|
| 受講形式 | オンライン講座:eラーニング形式 お好きな時間、お好きな場所でeラーニング形式にて受講いただけます。 |
| 前提となる知識・スキル | 必須スキル
推奨スキル
|
| 講座時間 | 動画講義約7時間半(演習時間除く) |
| 標準学習時間 | 約25時間 |
| 料金 | 275,000円/1名(税込) ※ 本講座は20名以上でのご受講のみです。教材改定のタイミングによりご提供できない場合がございます。 |
| 料金に標準で含まれるもの |
|
| 動画の視聴期間 | 動画共有日から1年間 |
| チャットの質問期間 | 講座チャンネルへの招待日から3ヶ月間 |
| お申し込み前の確認事項 |
|
| PCの動作環境 | ※8GB未満でも受講して頂くことは可能ですが、大きなデータを扱う演習の際に不具合が発生する可能性があります。 メモリ不足が原因の不具合についてはサポートすることができませんので、あらかじめご了承ください。容量の大きなデータを課題で扱いますので、より高スペックが望ましいです。 |
| 事前準備 |
|


FAQ
-
動画講義はいつまで視聴できますか?また、どうやって視聴しますか?視聴開始日ご提供日から1年間です。動画は、弊社ラーニングマネジメントシステム(LMS)にて視聴可能です。受講料のお支払い確認後、アカウント登録に関するメールをお送りします。
メール送信元:no-reply@skillupai-lms.com
※最新の教材提供を行うため、本コースは合成音声を利用する場合がございます。
受講者の声